SceneLine:AI驱动的配音练习平台
SceneLine:AI驱动的配音练习平台 🎬
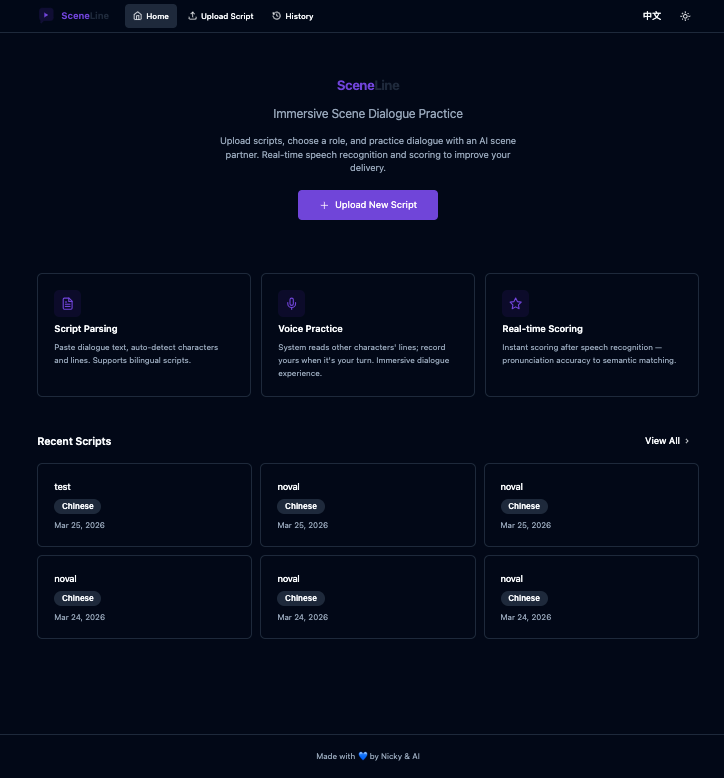
我最近发布了一个新项目 SceneLine — 一个 AI 驱动的配音练习平台,让语言学习者可以通过影视场景对话进行沉浸式配音训练。
为什么做这个?
语言学习中最难的往往不是词汇或语法,而是语感 — 那种自然的、地道的表达方式。传统的听力、阅读练习很难培养这种能力,而配音练习(Dubbing Practice)是很好的解决方案:
- 沉浸式场景 — 真实的影视对话,而非教科书式的句子
- 多角色互动 — 不同角色的语气、情绪、节奏
- 即时反馈 — 知道自己说得准不准
但传统配音练习有个痛点:没有反馈。你对着视频说了一遍,但不知道自己说得对不对。
SceneLine 要解决这个问题。
核心功能
🎙️ 实时语音识别(ASR)
- 使用 FunASR 进行语音识别
- 常驻进程模式,10 倍性能优化
- 实时对比你的发音和原台词
🔊 40+ TTS 声音
- Microsoft Edge TTS 支持
- 40+ 种声音选项
- 按性别/地区筛选,找到最适合的参考音
🎭 多角色对话练习
- 支持多角色场景(如《老友记》对话)
- 每个角色独立评分
- 可以一个人练多个角色
📊 练习历史与统计
- 三种视图模式:概览 / 按脚本 / 详情
- 追踪进步曲线
- 找出薄弱环节
📝 智能去重
- 基于内容哈希的脚本去重
- 自动合并相同内容,避免重复练习
技术栈
前端
- React + Vite — 快速开发体验
- Tailwind CSS — 简洁的 UI 设计
- TypeScript — 类型安全
后端
- Express + TypeScript — API 服务
- FunASR — 语音识别核心
- node-edge-tts — TTS 封装
AI/ML
- FunASR — 阿里达摩院开源的 ASR 框架
- ModelScope — 模型仓库
- faster-whisper — Whisper ASR 加速版
快速开始
一键启动(推荐)
git clone https://github.com/hugcosmos/SceneLine.git
cd SceneLine
./start.sh
首次启动会:
- 询问是否在中国大陆(自动配置镜像源)
- 下载 ASR 模型(约 2GB,首次需要 6-9 分钟)
然后访问 http://localhost:5000
Docker 部署
docker-compose up -d
系统要求
- Node.js: 20+
- Python: 3.9-3.11(ASR 依赖,torch 不支持 3.12+)
- 内存: 最低 4GB(ASR 模型约占用 2GB)
- 磁盘: 3GB+ 可用空间
- FFmpeg: 用于音频格式转换
项目结构
sceneline/
├── server/ # 后端 (Express + TypeScript)
│ ├── lib/ # 核心库 (ASR, TTS)
│ └── routes/ # API 路由
├── client/ # 前端 (React + Vite + Tailwind)
│ └── src/pages/ # 页面组件
├── shared/ # 共享类型定义
├── models/ # ASR 模型缓存
├── tts-cache/ # TTS 音频缓存
└── docker-compose.yml
许可证
MIT License — 完全开源,欢迎贡献。
后续计划
- 多人模式 — 支持多用户同时练习,实时对比
- 流式 ASR — 更快的实时识别,降低延迟
- 智能评分系统 — 更系统、更人性化的打分机制
- TTS 升级 — 支持更丰富的音色
- 多 TTS 供应商 — 集成更多 API 供应商(ElevenLabs、iFlytek、Baidu 等)
链接
- GitHub: github.com/hugcosmos/SceneLine
Made with 💙 by Nicky & AI